Discovery

Data Discovery
Discover Data across organization

Metadata Profiling
Auto-detect formats, anomalies, structure

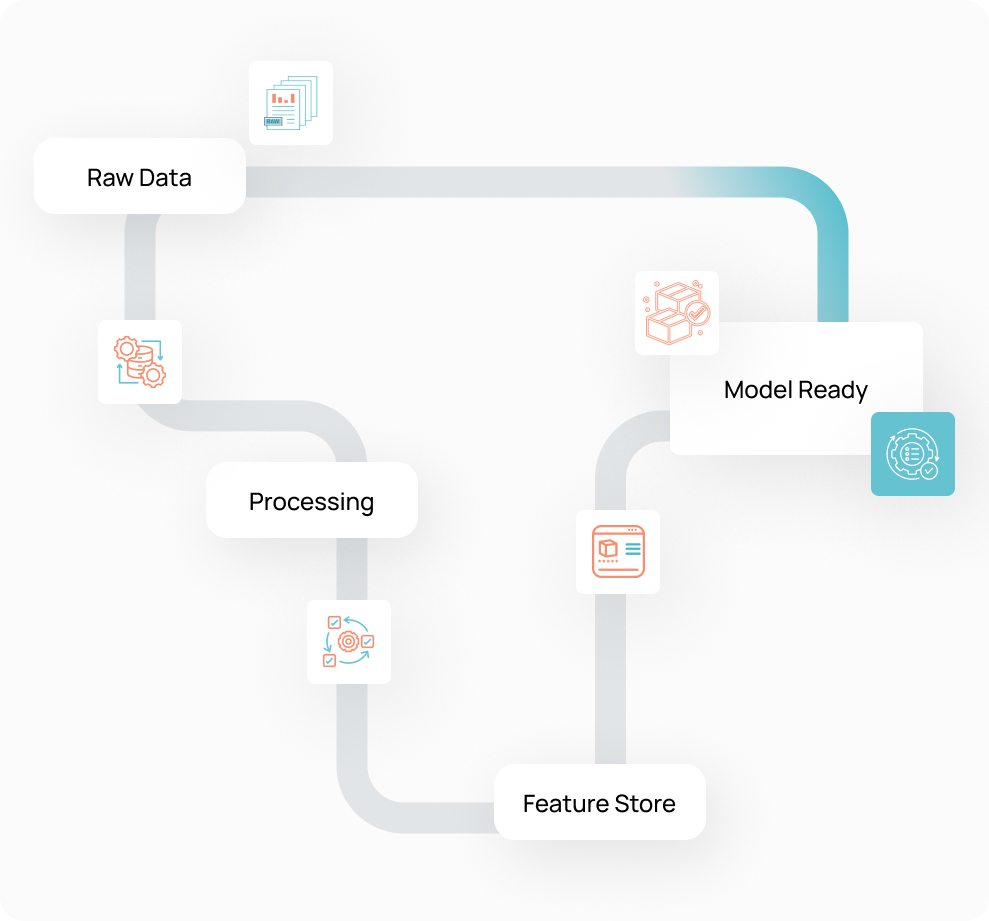
Ingestion Jobs
Schedule, monitor, and scale ingestion
Data Integrations
Plug into CRM, ERP, databases & more

Catalog

Data Catalog
Auto-enrich, tag, and unify data assets

Business Glossary
Align technical data with business meaning

Lineage
Trace data across pipelines to dashboards

Asset Classification
Classify assets based on types & groups